
| NB: When considering information concerning groups of people with ME/CFS and those with long COVID, it is important to remember that ME/CFS is a symptom-based clinical diagnosis not a mechanistic one. It is clear there is a high degree of shared pathophysiology between ME/CFS and long COVID, and the two diagnostic labels are not mutually exclusive. Importantly, some individuals with long COVID meet ME/CFS diagnostic criteria or could have a dual diagnosis. |
Key Points
- At present, we do not know how many people are living with LC in the UK or elsewhere in the world.
- We are not able to accurately determine the proportion of those with a COVID-19 infection who go on to develop LC.
- It is impossible to assess the proportion of those with LC who meet ME/CFS criteria, partly because it is not possible to identify all those with LC.
- We do know that LC prevalence is influenced by a wide range of factors, and that this makes calculating prevalence estimates – especially comparing prevalence rates – extremely difficult.
Introduction
At present, there is no clear estimate for the proportion of people who have long COVID (LC), either in the general population, or amongst only those who had a COVID-19 infection. It is also unclear what proportion of those with LC meet the various ME/CFS diagnostic criteria.
Although estimating the prevalence of an illness without a validated diagnostic biomarker is always going to be a complex task, the case for LC is more complicated than normal due to the number and intricacy of the factors that can influence a person’s risk of developing the illness.
In fact, research shows that the prevalence of LC is influenced by:
- Individual factors such as age, sex, and ethnicity.
- COVID-19 related factors such as COVID-19 variant, vaccine status, severity of acute illness, hospitalisation status, and number of reinfections.
- Study design and methods used, including where those with LC were recruited from, whether participants were followed up over time, how LC was defined, whether information was self-reported, collected from medical notes or gathered through assessment by a research team, and the sample size used.
- Geographical location.
Importantly, this not only means that existing estimates are extremely varied, but also that it may not be appropriate to compare prevalence estimates which are calculated using data from different sample populations; for example, across years or between countries, age groups, or those recruited using different methods.
Long COVID prevalence amongst those with a COVID-19 infection
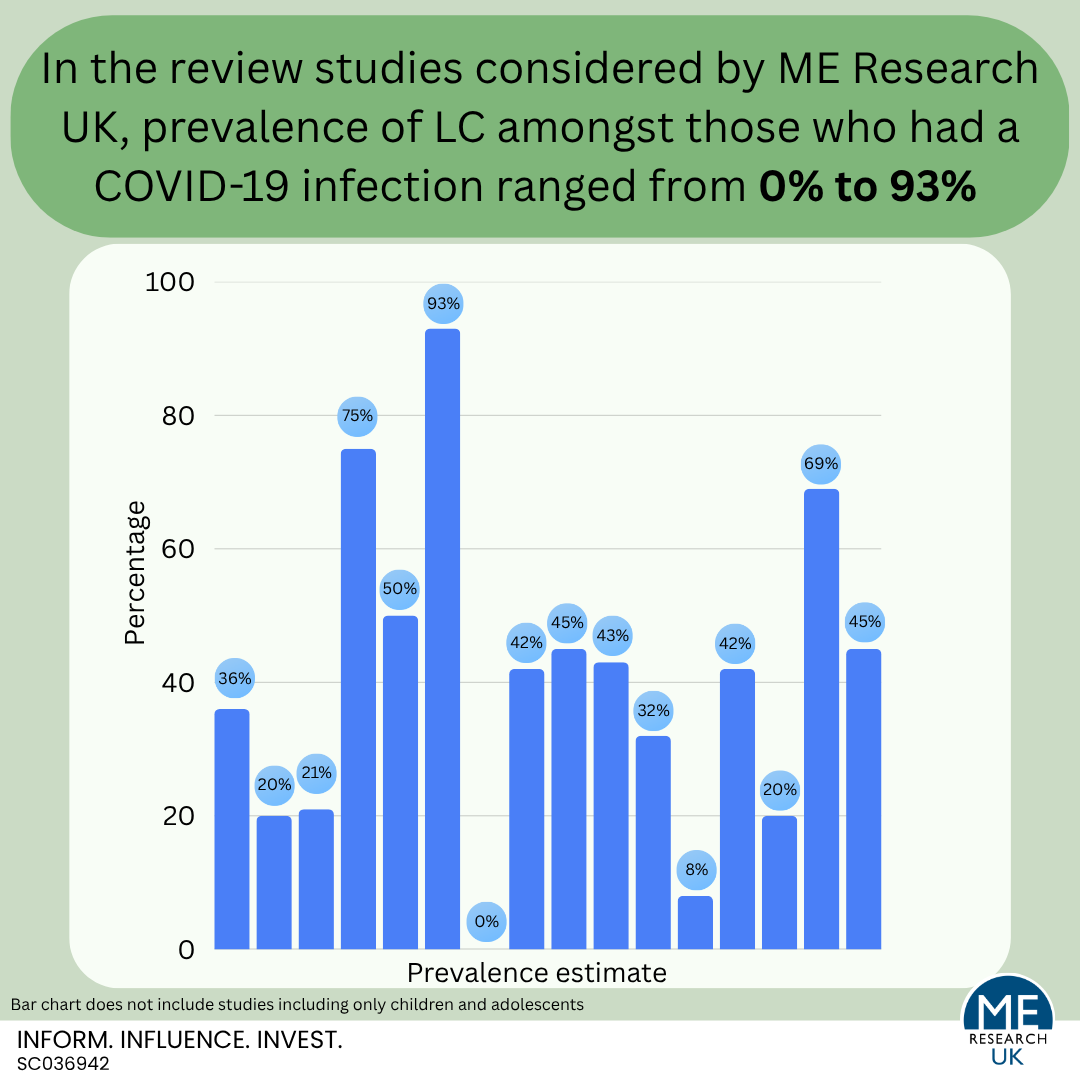
Many studies provide an estimate of the proportion of people with a COVID-19 infection who develop LC. Unfortunately, the definitions used for LC in these studies are inconsistent, and although systematic reviews – which combine prevalence estimates from different studies – have been published, the main conclusion these papers are able to draw is that there are high levels of diversity (heterogeneity) between studies. Importantly, this heterogeneity is reflected in the wide-ranging LC prevalence estimates; 0% to 93% for all ages, and 2% to 70% in studies of only children and adolescents.
Notably, many review studies emphasised that before conclusions relating to the prevalence of LC can be drawn, more research is needed – especially studies which define LC in line with standardised and routinely used criteria, and which follow participants up over time.
Long COVID prevalence in the general population (as opposed to only those who had a COVID-19 infection)
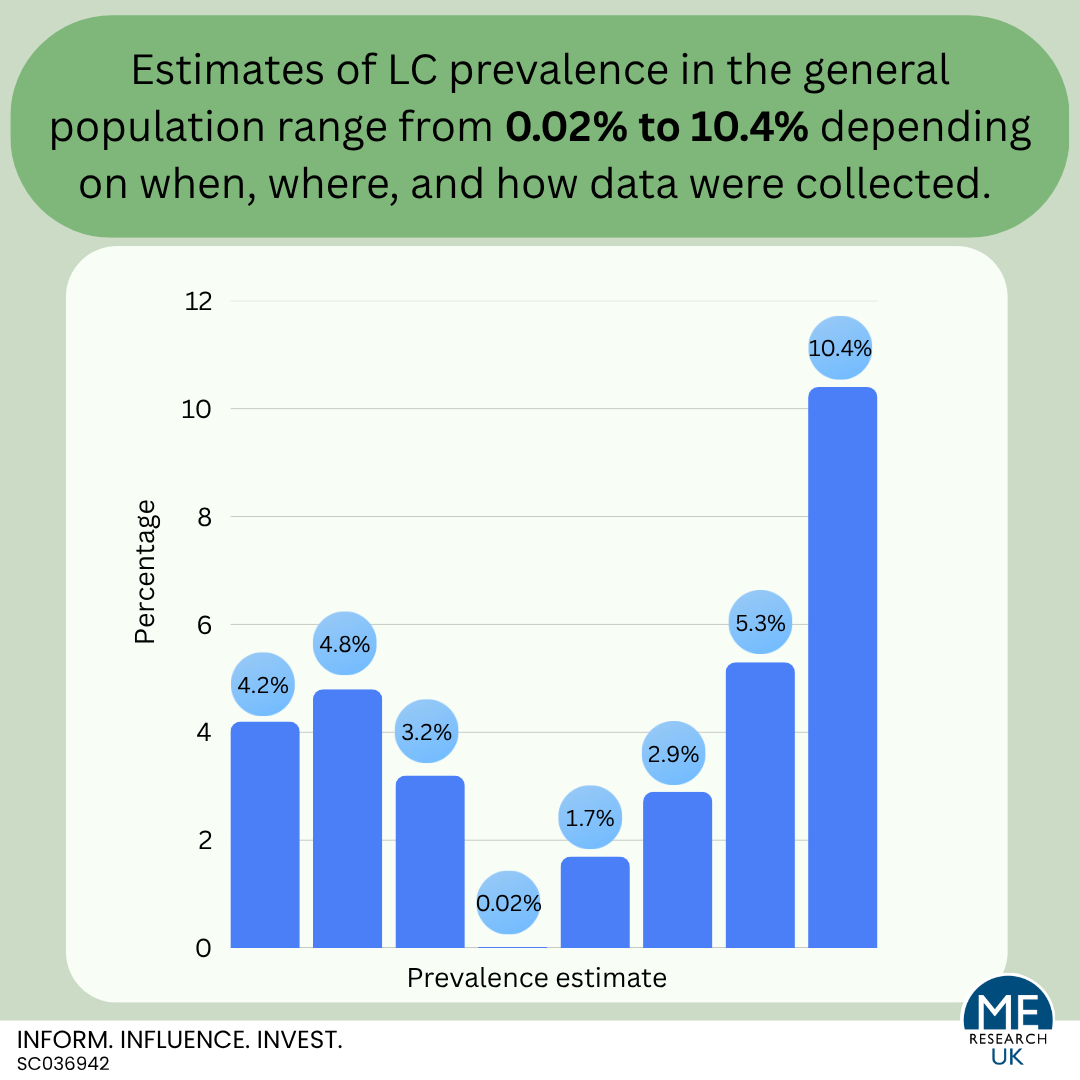
Evidence considering the proportion of people who have LC in the general population (as opposed to only those who had a COVID-19 infection) predominantly comes from self-reported survey data. Regrettably, self-reported data is often limited by misclassification bias – where participants report they have LC but may be experiencing symptoms due to another illness or do have ongoing symptoms caused by COVID-19 but would not describe themselves as having LC. It is also worth noting that for LC, evidence suggests that there may be higher proportions of those who are unsure whether they have LC in some minority groups than in others. This is important as it could mean that existing prevalence estimates may not be representative of everyone in the population and should be interpreted with caution.
The most recent estimate of LC in the general population is that, in 2025, 4.2% of over two million people registered with GP practices in England described themselves as having LC (still experiencing symptoms more than 12 weeks after they first had COVID-19 that are not explained by something else). Other estimates come from Scotland; 3.2% in 2024, the United Kingdom; 2.9% in 2023, and the USA; 5.3% in 2023. One study in Scotland provides LC prevalence estimates based on health record data and suggests that somewhere between 0.02% and 1.7% of the population have LC but that the proportion varies depending on how cases are identified within the medical records.
What proportion of those with LC meet ME/CFS diagnostic criteria?
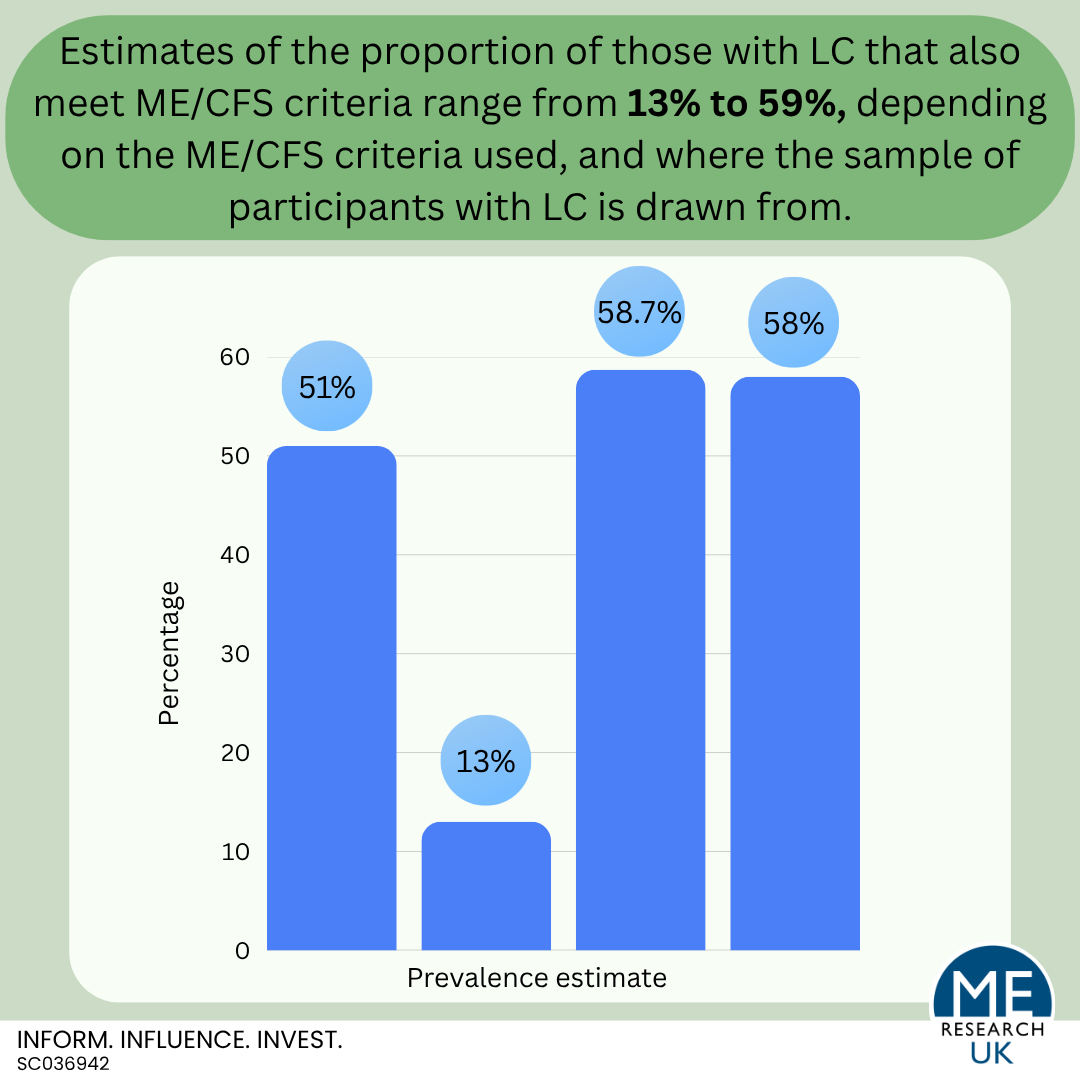
It is still unclear exactly what proportion of those with LC meet ME/CFS diagnostic criteria. Although recent estimates suggest between 13 and 59%, rates vary depending on the ME/CFS criteria used, and where the sample of participants with LC is drawn from.
Extrapolated figures for the UK
If the prevalence rate of 4.2% for self-reported LC in England identified by the GP patient survey in 2025 is applied to the provisional estimate for the population of the UK on 30 June 2025 (69,487,000 people), this would equate to approximately 2,918,454 people. However, this must be interpreted with caution as it may not be appropriate to extrapolate prevalence rates for the whole of the UK to England alone due to differences in population structure; e.g., in terms of age, ethnicity, rurality.
Alternatively, although again not for England alone, if the 2024 mid-year population estimate for England and Wales (61,806,682 people) was used alongside the 2024 prevalence rate (4.6%), this would equate to approximately 2,843,107 people.
If the most recent estimate of 51% for the proportion of those with LC meeting ME/CFS diagnostic criteria is applied to the above figures of 2,918,454 people or 2,843,107 people with LC, over 1,400,000 people would meet ME/CFS criteria. However, this must be interpreted with caution due to the limitations of existing research. For example, applying estimates based on predominantly those who attended LC clinics to the general population may overestimate the proportion of people with LC meeting ME/CFS diagnostic criteria.
What conclusions can be drawn?
In short, the conclusions that can be drawn based on existing research are as follows:
- At present, we do not know how many people are living with LC in the UK or elsewhere in the world.
- We are not able to accurately determine the proportion of those with a COVID-19 infection who go on to develop LC.
- It is impossible to accurately assess the proportion of those with LC who meet ME/CFS criteria, partly because it is not possible to identify all those with LC without a validated biomarker for the illness.
- We do know that LC prevalence is influenced by a wide range of factors, and that this makes calculating accurate prevalence estimates nearly extremely difficult.
Where next?
If researchers are to calculate a more accurate estimate for the prevalence of LC, ideally an operationalised biomarker for the disease is required. In the absence of such a biomarker, the only way to obtain a clearer estimate is to ensure consistency between studies going forward.
Key areas which would need to be considered are:
- Ensuring consistency in the way both LC and other variables like age, sex, ethnicity, and socioeconomic status are defined to better enable pooling and comparison of results.
- More representative study populations, inclusion of minority groups in research studies and consideration of the role intersectionality may play.
Where appropriate (and possible), it may also be useful to re-examine existing datasets focusing on estimating LC prevalence rates using data from populations with low heterogeneity (or ensuring analysis methods used account for heterogeneity); this may require some re-coding to ensure definitions are consistent, or potentially data linkage, which is the process of combining information from different sources (such as health records, social surveys, or administrative data) that relate to the same individual.
Also worth highlighting is a paper entitled “Considerations for epidemiological studies investigating post-acute infection syndromes (PAIS): Long COVID as a case study” which was published in the Lancet in March 2026. In the article, the researchers discuss limitations of existing LC research, and describe implications for future PAIS research.
Implications include:
- Anticipate that chronic illness will probably follow acute infection with a novel pathogen – This will prevent cases of PAIS being missed early in the pandemic (and prepare health professionals for the potential for ongoing illness).
- Involve people with lived experience in research – Inclusive patient and public involvement and engagement should be appropriately incorparated at all stages of research from project inception through to reporting.
- Define the disease as a priority – Either the development of a diagnostic test, or an internationally agreed definition for research purposes, and harmonisation of data collection tools such as surveys to increase comparability between studies.
- Timely implementation and adoption of diagnostic and referral codes in medical records.
- More studies that follow participants up over time, with regular data collection points.
- Incorporation of appropriate control groups into study designs.
- Reflect study sample heterogeneity in analysis methods used, and in reporting of results.
- Re-purpose existing outcome measures – e.g. those used to collect information on LC may be relevant (or relevant with minimal adaptation) for future PAIS research.
- Ensure there is more ‘ready to use’ data – the authors suggest that having ‘dormant cohorts’, which can be thought of as ‘ready to use’ studies, where groups of participants have been recruited and had initial data collected, but rather than going through active data collection phases, the project stays in a ‘maintenance’ state ready to be rapidly stood up in the event of a new pandemic.


